Der Chatbot sammelt regelmäßig Informationen von Webseiten, die von euch hinterlegt werden, um Fragen der Nutzenden besser zu beantworten. Dafür erfasst er nächtlich die Textinhalte der hier hinterlegten Seiten (= Crawling) und speichert deren Textinhalte in einer Datenbank ab (= Indizierung / Indexierung). Wenn du Änderungen an den Einstellungen vornimmst, dauert es bis zur nächsten nächtlichen Indizierung, bis die neuen Inhalte verfügbar sind – der Chatbot schaut sich jede Seite erst beim nächtlichen Indizieren an.
Quellen hinzufügen und ausschließen
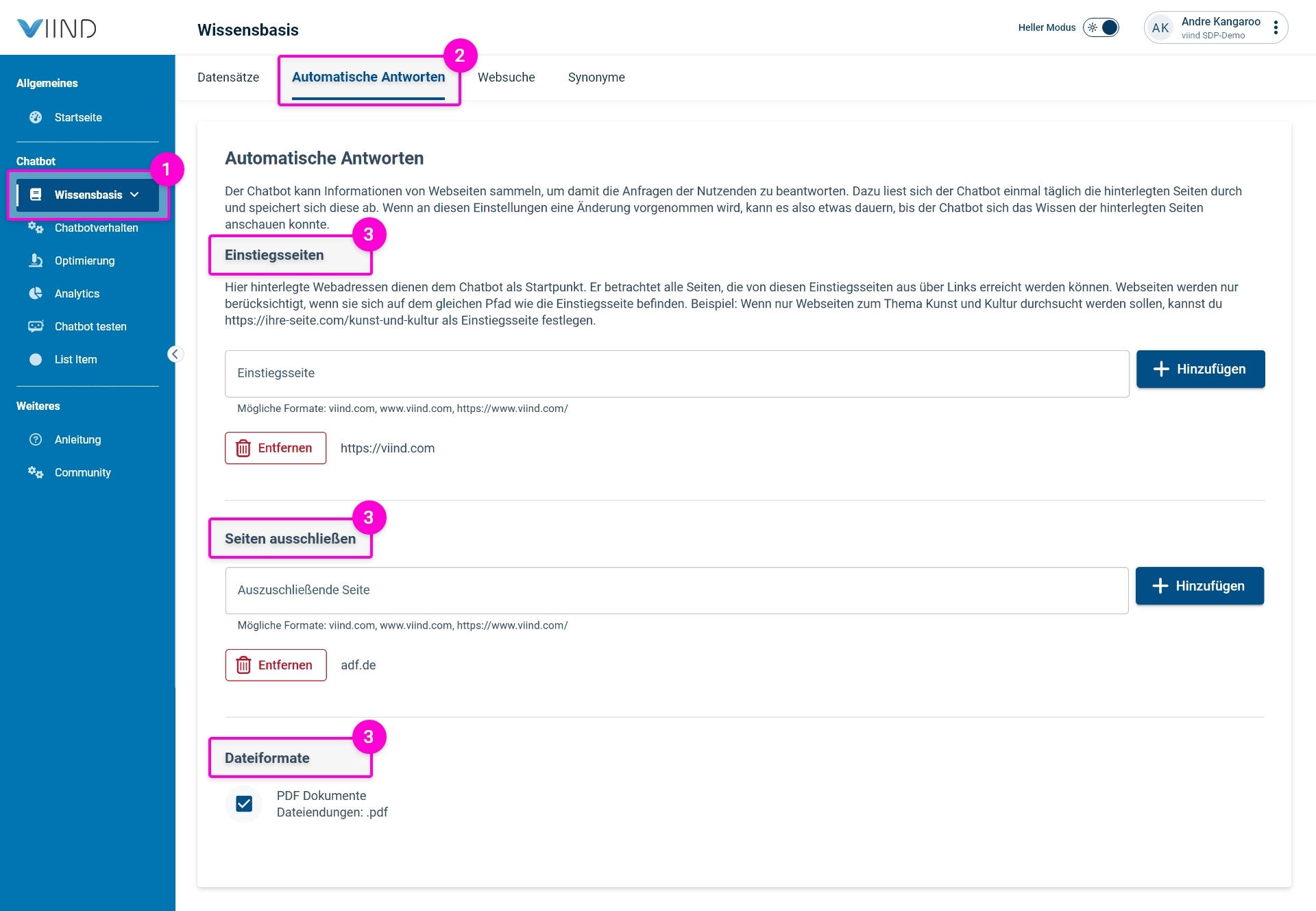
Navigiere im Admincenter zur „Wissensbasis“ (siehe Markierung 1)und klicke oben auf den Reiter „Automatische Antworten“(siehe Markierung 2).
In diesem Bereich stehen dir jetzt neue Einstellungen (siehe Markierung 3) zur Verfügung, die im Folgenden erläutert werden.
Einsstiegsseiten für die Inhaltserfassung
Hier legst du fest, wo der Chatbot mit dem nächtlichen Einsammeln von Inhalten beginnt.
So funktioniert das Crawling (Erfassen der Website-Inhalte) - Schritt für Schritt
Unser Crawler arbeitet sich von den hinterlegten Einstiegsseiten aus schrittweise voran, um Inhalte zu erfassen.
Schritt 1: Start an den Einstiegsseiten Der Chatbot beginnt an jeder von dir hier hinterlegten URL (Einstiegsseite) und durchsucht deren Textinhalte.
Schritt 2: Verfolgung passender Links Auf jeder Einstiegsseite schaut sich der Chatbot alle verlinkten Seiten an. Wichtig: Er folgt aber nur Links zu Seiten, deren URL mit demselben Pfad wie eine deiner hinterlegten Einstiegsseiten beginnt.
Schritt 3: Weiterverfolgung Auf allen so gefundenen Seiten wiederholt sich der Prozess: Der Chatbot folgt wieder allen Links, die mit einem deiner Einstiegspfade beginnen - immer weiter, bis keine neuen passenden Seiten mehr gefunden werden.
Schritt 4: Speicherung Alle gefundenen Textinhalte werden in der viind-Datenbank gespeichert (indiziert) und bilden die Grundlage für automatische Antworten.
Praktisches Beispiel: Welche Inhalte werden erfasst, welche nicht?
Beispiele für Seiten, deren Inhalte der Crawler erfasst und für Seiten, die nicht berücksichtigt werden.
Deine hinterlegten Einstiegsseiten:
https://www.musterstadt.de
Was passiert beim Crawling?
✅ Die Inhalte dieser Seiten erreicht der Crawler:
https://www.musterstadt.de/aktuelles → beginnt mit https://www.musterstadt.de
https://www.musterstadt.de/gesundheit/hitzeschutz → beginnt mit https://www.musterstadt.de/
❌ Diese Seiten werden NICHT verfolgt, selbst wenn sie auf einer Seite, die der Crawler erreicht, verlinkt sein sollten:
https://serviceportal.musterstadt.de/kontakt → andere Subdomain, beginnt nicht mit deinem Einstiegspfad
https://www.musterstadt.de/microsites/landingpage1 → spezielle Mikroseite, welche nirgends über Seiten der Hauptdomain verlinkt ist
https://www.anderestadt.de/kooperation → andere Domain
https://www.facebook.com/musterstadt → externe Seite
Weitere Tipps für die optimale Konfiguration
Vollständigkeit sicherstellen: Wenn du möchtest, dass auch Subdomains wie serviceportal.musterstadt.de oder spezielle Bereiche wie musterstadt.de/microsites/landingpage1 gecrawlt werden, musst du diese als separate Einstiegsseiten hinzufügen.
Mehrfach verlinkte Seiten: Wird eine Seite (also die exakt selbe URL) mehrfach verlinkt, wird ihr Inhalt nur einmal gespeichert – das System erkennt das automatisch.
Flexible Bereiche: Anstatt dem Chatbot Hauptseiten (wie www.musterstadt.de) als Quelle zur Verfügung zu Stellen, kannst du auch nur spezifische Unterbereiche (wie www.musterstadt.de/gesundheit) als Einstiegspunkt wählen. Das ist nützlich, wenn du den Chatbot nur auf bestimmten Bereichen der Website erscheinen lässt oder ihm nur bestimmte Themenbereiche einer Website als Wissensquelle mitgeben möchtest, anstatt die gesamte Website zu durchsuchen.
Hinweis zum Whitelisten des Crawlers
In manchen Fällen blockiert eine Website unseren Crawler - also die Software, die sich nächtlich die Texte von einer Website kopiert und in unserer Datenbank abspeichert. In diesem Fall muss die Website unseren User Agent zulassen: "viindCrawler/2.0 (https://www.viind.com/impressum/)”
Wende dich dazu an deinen Website-Beauftragten, eine Person aus der Entwicklung oder an deine zuständige Agentur.
Hinweis zu hinterlegten URLs, die per „Client Side Rendering" laden
Diese können derzeit nicht vollständig von unserem Crawler (also der Software, die sich nächtlich die Texte von einer Website kopiert und in unserer Datenbank abspeichert) erfasst werden. Detaillierte Infos dazu ganz unten im FAQ.
Seiten ausschließen (optional)
Du kannst hier bestimmte Seiten davon ausschließen, vom Chatbot gelesen zu werden – entweder durch das Eintragen kompletter URLs oder mit Hilfe von Regex- Mustern (für Erklärung siehe Info-Icon).
Ausschluss per URL-Struktur: Trage hier eine URL ein, um diese Seite sowie alle Seiten darunter (auf Basis der sprechenden URL-Struktur) von der Indizierung auszuschließen.
Es werden alle Seiten ausgeschlossen, die hierarchisch in der sprechenden URL unterhalb der eingetragenen Adresse liegen.
Ausschluss per Regex: Nutze reguläre Ausdrücke (Regex), um Seiten flexibler auszuschließen – z. B. basierend auf Schlagwörtern oder URL-Mustern.
Beispiel: .veranstaltung. schließt alle URLs aus, die das Wort „veranstaltung“ enthalten.
Regex steht für „Regular Expressions“ – das sind Muster zur Erkennung bestimmter Zeichenfolgen im Text. Falls du dir unsicher bist: Frag ChatGPT nach einem passenden Regex oder nutze Seiten wie http://regex101.com zum Erstellen und Testen.
Erklärvideo
Im Video erklärt Philipp nochmal Schritt für Schritt, wie ihr Regex im Admincenter nutzen könnt und worauf ihr dabei achten solltet:
Dateiformate (optional)
Hier kannst du festlegen, ob von deinen hinterlegten Einstiegsseiten (siehe oben) auch Inhalte aus PDF-Dokumenten beim Indizieren berücksichtigt werden sollen. Wenn diese Option aktiviert ist, werden PDF-Dateien auf den hinterlegten Seiten nach auslesbarem Text durchsucht.
Wichtig: Enthält ein PDF nur gescannte Bilder von Text (z. B. eingescanntes Papier), kann der Inhalt nicht verarbeitet werden. Auch Grafiken oder Diagramme in PDFs werden nicht gespeichert – nur reiner Text wird vom Chatbot als Information übernommen.
FAQ
Warum können Websites mit „Client Side Rendering" derzeit nicht vollständig erfasst werden?
Was ist Client Side Rendering (CSR)?
Manche moderne Websites verwenden eine spezielle Technologie namens „Client Side Rendering" (CSR). Das bedeutet vereinfacht gesagt:
Normale Website: Wenn du eine Seite aufrufst, wird der komplette Inhalt sofort geladen – wie beim Aufschlagen eines Buchs, wo du direkt den ganzen Text siehst.
Website mit Client Side Rendering: Der Inhalt wird erst nach und nach aufgebaut, nachdem die Seite geladen wurde – ähnlich wie bei einem Puzzle, das sich Stück für Stück zusammensetzt.
Warum ist CSR aktuell ein Problem für den viind-Chatbot?
Unser Crawler (die Software, die nächtlich deine Website-Inhalte sammelt) funktioniert wie ein sehr schneller Leser: Er „schaut" einmal auf eine Seite und speichert ab, was er sofort sehen kann.
Bei Websites mit Client Side Rendering ist beim ersten „Hinschauen" oft noch nicht der vollständige Inhalt da – dieser wird erst später durch zusätzliche Programmierung nachgeladen. Deshalb kann unser Crawler diese Inhalte derzeit noch nicht erfassen.
Woran erkennst du, ob deine Website betroffen ist?
Wenn Inhalte erst nach dem Laden der Seite erscheinen (z.B. durch Animationen)
Bei Single-Page-Applications (SPAs)
Bei Websites, die stark auf JavaScript basieren
Wenn der viind-Crawler trotz korrekter URL-Eingabe keine oder nur wenige Inhalte findet
Was kannst du in diesem Fall tun?
Falls du vermutest, dass deine Website Client Side Rendering verwendet und wichtige Inhalte nicht vom Chatbot erfasst werden, melde dich bitte unter support@viind.com.
JavaScript errors detected
Please note, these errors can depend on your browser setup.
If this problem persists, please contact our support.